在前面的案例中已经将Spark Streaming整合了,但是你会发现,那个程序只能实时计算当前输入的一条数据,并不能做到累加,所以下面的代码就是解决这个问题的,我们依然以词频统计为例
1.首先放出代码: package cn.ysjh import org.apache.spark.{HashPartitioner, SparkConf} import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.kafka.KafkaUtils import org.apache.spark.streaming.{Seconds, StreamingContext} object StateSparkStreaming { //* 该函数需要传入一个迭代器,再返回一个迭代器 第一个参数:聚合的key,这里就是指单词 第二个参数:所有小批次单词出现的次数 第三个参数:初始值或累加的中间结果 /*/ val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => { iter.map(t=>(t._1,t.2.sum+t.3.getOrElse(0))) // iter.map{ case (x,y,z)=>(x,y.sum+z.getOrElse(0))} } def main(args: Array[String]): Unit = { val conf: SparkConf = new SparkConf().setAppName(“SparkStreamingKafka”).setMaster(“local[4]”) val streaming: StreamingContext = new StreamingContext(conf, Seconds(5)) //要想能够累加,就需要把中间结果保存起来,最好保存到hdfs中 streaming.checkpoint(“hdfs://cdh0:8020/opt/ys/test”) val zkAddress = “cdh0:2181,cdh1:2181,cdh2:2181” val groupID = “g1” val topic = Map[String, Int](“first” -> 1) //创建DStream,需要KafkaDStream val data: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(streaming, zkAddress, groupID, topic) //对数据进行处理,Kafka的ReceiverInputDStream[(String, String)]里面装的是一个元组(key是写入的key,value是实际写入的内容) val lines: DStream[String] = data.map(.2) val word: DStream[String] = lines.flatMap(.split(" “)) val words: DStream[(String, Int)] = word.map((, 1)) //updateFunc是一个函数,HashPartitioner是指定分区数,streaming.sparkContext.defaultParallelism是默认的分区数,true表示以后依然使用这个分区数 val result = words.updateStateByKey(updateFunc, new HashPartitioner(streaming.sparkContext.defaultParallelism), true) result.print() streaming.start() streaming.awaitTermination() } }
2.因为这里主要看的是是否能够累加计算,所以我们将不必要的日志去掉,只打印关键的日志,所以在项目中添加log4j.properties
/# Global logging configuration log4j.rootLogger=WARN, stdout /# Console output… log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p [%t] - %m%n
3.打开Kafka集群,并启动一个生产者,在主题first中添加数据
4.运行程序
运行截图:
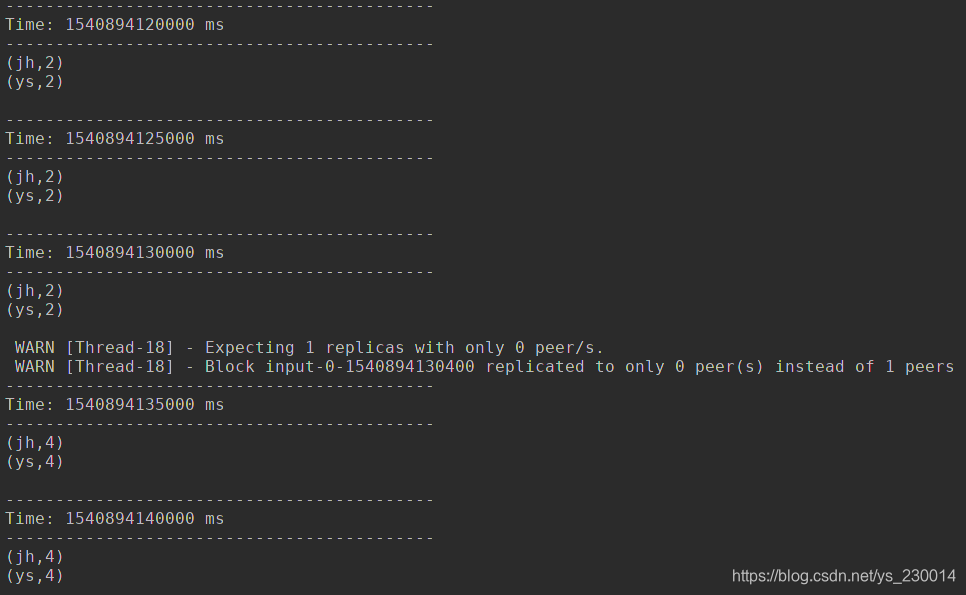
可以看出,每个5秒产生一个批次,然后进行计算统计,并且能够累加之前的数据进行计算
注意:
这里看起来已经很成功了,但是千万不要以为在企业公司中就是这样做的,因为你可以明显的发现,上边的程序停掉以后再重新运行,并不会把之前的数据累加在内,不能记录上次读取数据的位置,所以实际生产中并不这样做
最后修改于 2018-10-30

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。