hadoop集群部署分为三种:
本地部署 伪分布式部署 分布式部署
分布式部署顾名思义前提要有至少多台服务器,所以这里只介绍前两种部署方式,但是本地部署非常简单,只有几步,按照官方文档完全可以进行,所以下面主要讲伪分布式部署方式
伪分布式:
1.准备工作:
在linux环境下安装jdk和hadoop,上传压缩包—-》解压—-》检验是否安装成功
2.在core-site.xml(全局配置文件)中进行如下配置:
第二个标签里面的是为了覆盖默认配置,为了完整性,需要自己生成一个目录
在hdfs-site.xml中进行如下配置:
hdfs文件系统分为namenode主节点和datanode从节点,namenode是用来存储元数据的,datanode才是存储数据的,datanode的存储分布都是通过namenode进行的,namenode通常会将数据复制3份副本存储在不同的服务器上,这里只有一台机器所以才配置为1
3.启动namenode和datanode:
首先需要初始化hdfs:
bin/hdfs namenode -format
然后启动namenode和datanode:
sbin/hadoop-daemon.sh satrt namenode
sbin/hadoop-daemon.sh satrt datanode
使用jps查看:
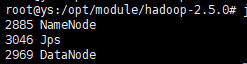
namenode的web界面:ip+50070
在hdfs中操作都要使用命令bin/hdfs dfs,创建文件,查看,删除都要用这个命令,
在hdfs中运行wordcount:
首先创建文件夹:bin/hdfs dfs -mkdir -p /user/ys/mapreduce
然后上传文件(因为不能创建文件,所以只能用上传和下载):bin/hdfs dfs -put ys.input /user/ys/mapreduce/
这时候再运行wordcount程序,就是在hdfs下运行的了,因为前面已经配置过core-site.xml了,所以不会在本地找,会在hdfs下找,运行结果跟本地一样
4.配置单节点上的yarn
首先修改yarn-env.sh中的JAVA_HONE路径(可以不修改)
然后配置yarn-site.xml:
配置slaves:(从节点机器的地址配置)在里面加上从节点机器(datanode)的地址
最后启动nodemanager和resourcemanager:
sbin/yarn-daemon.sh start nodemanager
sbin/yarn-daemon.sh start resourcemanager
使用jps查看:
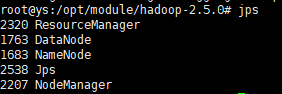
resourcemanager的web界面:ip+8088
现在要让mapreduce运行在yarn上,要对mapred-site.xml进行配置,为保证不出错,对mapred-env.sh的JAVA_HOME进行修改:
5.启动历史服务:
启动JobHistoryServer: sbin/mr-jobhistory-daemon.sh start historyserver
这时候在ip+8088的web界面可以点击History,会跳转到history界面
6.日志聚集功能的开启:
应用完成之后,将日志信息上传到HDFS系统上
在yarn-site.xml上配置:
第一个是开启上传日志的功能,第二个是配置日志的保存时间
7.开启SecondaryNameNode:
在hdfs-site.xml中配置:
然后启动SecondaryNameNode
8.三种启动方式
1).各个服务组件逐一启动
2).各个模块进行启动:
首先要生成公钥:
进入root目录下的.ssh目录,然后输入一下命令:
ssh-keygen -t rsa

rsa是其中的一种加密算法,会在.ssh目录下生成一个公钥一个私钥,然后执行一下命令将公钥复制到从节点机器上
ssh-copy-id 主机名,就可以直接使用ssh 主机名 远程登录到其他机器上,在主节点机器上也可以使用模块启动和关闭组件了
3)全部启动
总结:
hadoop 2.x:
hdfs:存储数据
NameNode:存储文件系统的元数据,命名空间namespace
DataNode:存储数据
SecondaryNameNode:辅助NameNode工作的,合并两个文件(定时周期性)如果在hdfs中有两个NameNode,就没有 SecondaryNameNode
yarn:数据操作系统
yarn是将资源放在Container(容器)中
ResourceManager:
对整个集群资源进行管理和调度
NodeManager:
管理每个节点的资源和调度
最后修改于 2018-05-25

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。