MapReduce执行流程Shuffle
Shuffle:
/*洗牌或者弄乱的意思
/*Collections.shuffle(List):随机得打乱参数里的元素顺序
/*MapReduce里Shuffle:描述着数据从map task输出到reduce task输入的这段过程
下面就详细介绍Shuffle这段过程:
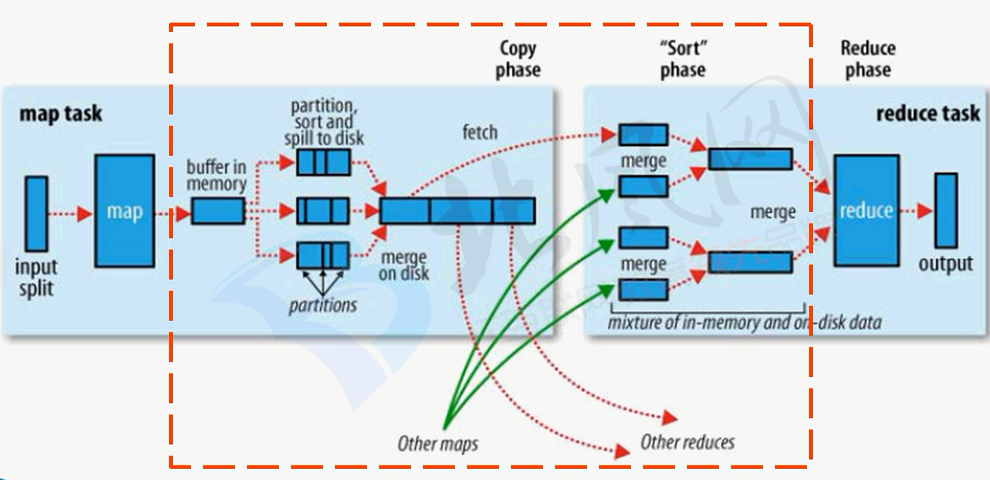
/*map task输出的<key,value>对,首先先放在内存(memory)中,然后会spill,溢写到磁盘中,即在内存中溢出就会自动写到磁 盘中,并且会这些文件进行分区(parttition)和排序(sort),分区是因为reduce有多个,这时候可能会有多个小文件,然后会将 这些小文件再进行合并(merge)和排序成大文件,而这些大文件在Map Task运行的机器的本地磁盘上,至此map任务才算彻底 结束
/*这时Reduce Task任务就会启动
/*copy: Reduce Task会回到Map Task运行的机器上,拷贝要处理的数据
/*合并,排序·
/*分组: 将相同key的value放在一起
以上就是Shuffle的过程,Map输入的数据类型与Reduce输出的数据类型一致
总的来说:
/*分区
/*排序
/*拷贝
/*分组
以上四部只有拷贝是用户无法干预的,其他的都可以进行设置,例如设置分区的大小,排序的算法等操作,但是还有可以优化的地方,例如在将小文件合并成大文件的时候,可以进行压缩,这样即占用磁盘空间少,在拷贝的时候也够快速,还有就是在进行分区后可以将相同的进行combiner合并操作,这两个优化都是视具体情况而定的
最后附上Shuffle流程图:
最后修改于 2018-06-01

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。