1.需求场景
访问日志: 201801,zs 201802,ls 201803,ww …..
黑名单:
zs,ls…
现在需要把黑名单中的人从访问日志中给过滤掉,然后得到一份新的访问日志
2.思路分析
要实现上边的需求,首先要进行思路分析,即如何实现
我们可以把黑名单数据先变成一个RDD,将它变成(zs,true) (ls,true)这样的形式,然后再将访问日志变成(zs,<201801,zs>) (ls,<201802,ls>) (ww,<201803,ww>)的形式,使用leftjoin把它们变成(zs,[<201801,zs>,true]) (ls,[<201802,ls>,true]) (ww,[<201803,ww>,true])的形式,如果是true的话就输出
3.代码实现 package cn.ysjh import org.apache.spark.SparkConf import org.apache.spark.rdd.RDD import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream} import org.apache.spark.streaming.{Seconds, StreamingContext} object TranFormSpark { def main(args: Array[String]): Unit = { val cf: SparkConf = new SparkConf().setAppName(“TranForm”).setMaster(“local[2]”) val stream: StreamingContext = new StreamingContext(cf,Seconds(5)) //* 构建黑名单 /*/ val block = List(“zs”,“ls”) val blocks: RDD[(String, Boolean)] = stream.sparkContext.parallelize(block).map(x => (x,true)) val socket: ReceiverInputDStream[String] = stream.socketTextStream(“192.168.220.134”,6789) val result: DStream[String] = socket.map(x => (x.split(",")(1), x)).transform(rdd => { rdd.leftOuterJoin(blocks) .filter(x => x._2._2.getOrElse(false) != true) .map(x => x._2._1) }) result.print() stream.start() stream.awaitTermination() } }
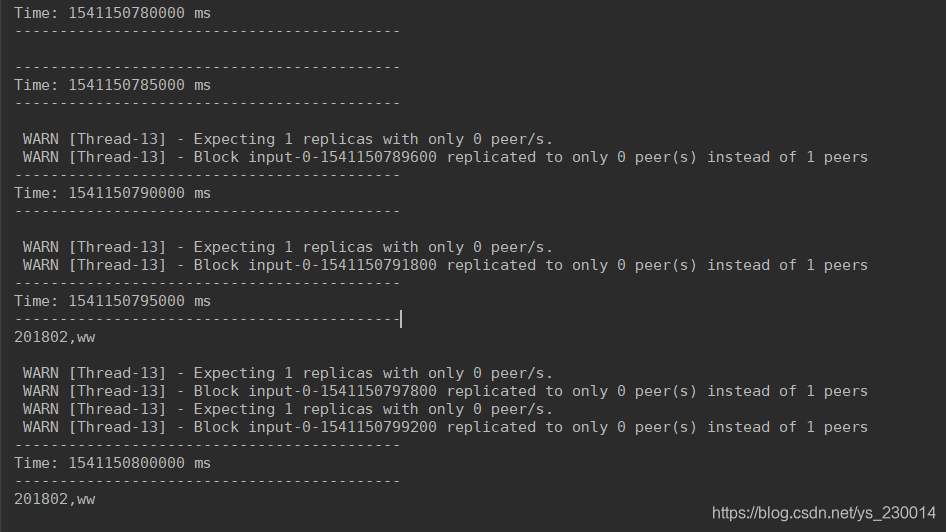
4.运行测试
在虚拟机中使用nc来输送socket数据,,然后看在IDEA中Spark Streaming程序的运行结果
最后修改于 2018-11-02

本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。